只包含DML(Data Manipulation Language,数据操纵语言)的内容,不包含DDL(Data Definition Language,数据定义语言)和DCL(Data Control Language,数据控制语言)
基础语法
仅举例说明,不做过多解释
其中Student表为学生信息表,Score表为学生成绩表,建表语句为:
CREATE TABLE Student (
s_id VARCHAR(20) COMMENT 'student ID',
s_name VARCHAR(20) NOT NULL DEFAULT '' COMMENT 'student name',
s_birth VARCHAR(20) NOT NULL DEFAULT '' COMMENT 'student birthday',
s_sex INT(1) COMMENT 'student sex',
PRIMARY KEY (s_id)
);
CREATE TABLE Score (
s_id VARCHAR(20) COMMENT 'student ID',
c_id VARCHAR(20) COMMENT 'course ID',
s_score INT(3) COMMENT 'student score',
PRIMARY KEY (s_id, c_id)
);
以下为包含基础语法的查询语句:
SELECT * FROM Student WHERE s_name LIKE "李%";
SELECT s_id, s_score FROM Score WHERE c_id IN ("01", "02");
SELECT COUNT(DISTINCT s_id) FROM Score WHERE s_score >= 60;
SELECT c_id FROM Score WHERE s_score<60 ORDER BY c_id DESC;
SELECT s_id, s_score FROM Score WHERE c_id="03" AND s_score<60 ORDER BY s_score DESC, s_id;
# HAVING通常跟在GROUP BY后面,对分组进行筛选
SELECT s_id, AVG(s_score) AS avg_score FROM Score GROUP BY s_id HAVING AVG(s_score)>60;
SELECT s_id, s_name, s_birth FROM Student WHERE YEAR(s_birth) = 2010 LIMIT 10;
SELECT * FROM Student WHERE MONTH(s_birth) = MONTH(NOW());
# 求年纪
SELECT s_id, s_name, s_birth, FLOOR(TIMESTAMPDIFF(MONTH, s_birth, NOW())/12) FROM Student;
进阶语法
条件表达式
case表达式
/*
语法
CASE WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
.
ELSE <表达式>
END
*/
# 将s_sex字段的数值转成'male'、'female'和'null'的表示形式
SELECT s_id, s_name,
(CASE s_sex WHEN 1 THEN "male" WHEN 2 THEN "female" ELSE "uncertain" END) AS gender
FROM Student;
# 行转列
SELECT
SUM(CASE s_sex WHEN 1 THEN 1 ELSE 0 END) AS "male",
SUM(CASE s_sex WHEN 2 THEN 1 ELSE 0 END) AS "female"
FROM Student;
if表达式
/*
语法
IF(expr1, expr2, expr3)
expr1的值为 TRUE,则返回值为expr2
expr1的值为FALSE,则返回值为expr3
*/
SELECT IF(s_sex = 1, "male", "female") AS gender
FROM Student WHERE s_sex != "";
/*
语法
IFNULL(expr1, expr2)
判断expr1是否为NULL:
如果expr1不为空,返回expr1;
如果expr1为空, 返回expr2
*/
SELECT IFNULL(s_sex, "uncertain") AS gender
FROM Student;
子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询,子查询的结果可以作为一个表,也可以作为一个过滤条件
# 子查询作为一个表
# 前10名从低到高排序
SELECT *
FROM (
SELECT * FROM Score
WHERE c_id = "01"
ORDER BY s_score DESC LIMIT 10
) AS t
ORDER BY s_score;
# 子查询作为一个过滤条件
# 高于平均分
SELECT * FROM Score
WHERE s_score >= (
SELECT AVG(s_score) FROM Score
);
表关联
UNION
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
UNION 是去重的,UNION ALL 是不去重的,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后。
# UNION去重
SELECT s_id, s_score FROM Score WHERE c_id = "01"
UNION
SELECT s_id, s_score FROM Score WHERE c_id = "02"
ORDER BY s_score;
# UNION ALL不去重
SELECT s_id, s_score FROM Score WHERE c_id = "01"
UNION ALL
SELECT s_id, s_score FROM Score WHERE c_id = "02"
ORDER BY s_score;
JOIN
常见的7种JOIN方式见下图:
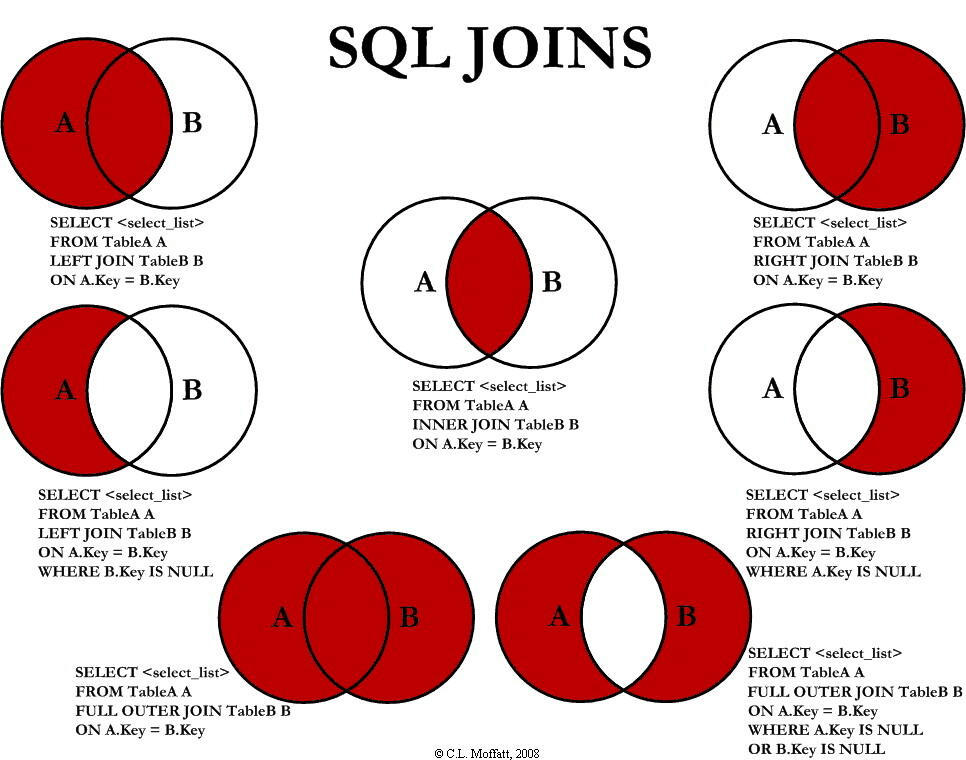
# 列出学生ID、学生姓名的同时也把对应学生的分数列出来
SELECT st.s_id, st.s_name, sc.c_id, sc.s_score
FROM Student st
LEFT JOIN Score sc ON st.s_id = sc.s_id;
| s_id | s_name | c_id | s_score |
|---|---|---|---|
| 01 | 李四 | 03 | 99 |
| 01 | 李四 | 02 | 90 |
| 01 | 李四 | 01 | 80 |
| 02 | 王二 | 03 | 80 |
| 02 | 王二 | 02 | 60 |
查询语句运行结果中需要注意,Student表中原本的一条数据被重复了N次
窗口函数
窗口函数的语法为:
<窗口函数> OVER ([PARTITION BY <分组列名>] ORDER BY <排序列名>)
MySQL中只有8.0版本以上才支持窗口函数
# 按照c_id分组,按照s_score排序
SELECT s_id, c_id, s_score,
rank() OVER (PARTITION BY c_id ORDER BY s_score DESC) AS ranking
FROM Score;
| s_id | c_id | s_score | ranking |
|---|---|---|---|
| 01 | 01 | 80 | 1 |
| 03 | 01 | 80 | 1 |
| 05 | 01 | 76 | 3 |
| 02 | 01 | 70 | 4 |
| 04 | 01 | 50 | 5 |
| 06 | 01 | 31 | 6 |
| 01 | 02 | 90 | 1 |
| 02 | 02 | 60 | 2 |
| 04 | 02 | 30 | 3 |
| 01 | 03 | 99 | 1 |
排序函数
三种不同排序函数:rank(),dense_rank(),row_number()
# 按成绩排序,展示三种不同排序函数的差异
SELECT s_id, c_id, s_score,
rank() OVER (ORDER BY s_score DESC) AS ranking,
dense_rank() OVER (ORDER BY s_score DESC) AS denserank,
row_number() OVER (ORDER BY s_score DESC) AS rownumber
FROM Score;
| s_id | c_id | s_score | ranking | denserank | rownumber |
|---|---|---|---|---|---|
| 01 | 03 | 99 | 1 | 1 | 1 |
| 07 | 03 | 98 | 2 | 2 | 2 |
| 01 | 02 | 90 | 3 | 3 | 3 |
| 01 | 01 | 80 | 4 | 4 | 4 |
| 02 | 03 | 80 | 4 | 4 | 5 |
| 03 | 01 | 80 | 4 | 4 | 6 |
| 05 | 01 | 76 | 7 | 5 | 7 |
| 02 | 01 | 70 | 8 | 6 | 8 |
rank():有相同分数时排名相同,且会占用后一名的位置,一些名次不存在,存在名次跳跃
dense_rank():有相同分数时排名相同,但不会占用后一名的位置,名次是连续的
row_number():有相同分数时排名也会不相同,名次是连续的
聚合函数
在窗口函数中使用聚合函数(sum,avg,count,max,min)的含义为:根据order by字段的排序,求”到目前为止“的聚合值,比如sum就是累加的含义。语言描述起来有点困难,直接看查询语句的结果理解起来就不难了。
- 按照s_score字段降序排列。值得注意的是:相同分数count值相同。因为降序,最大分数值出现在第一位,所以每一行的max都等。
#只有order by,没有partition的查询
SELECT s_id, c_id, s_score,
SUM(s_score) OVER (ORDER BY s_score DESC) AS current_sum,
AVG(s_score) OVER (ORDER BY s_score DESC) AS current_avg,
COUNT(s_score) OVER (ORDER BY s_score DESC) AS count_,
MAX(s_score) OVER (ORDER BY s_score DESC) AS max_score,
MIN(s_score) OVER (ORDER BY s_score DESC) AS min_score
FROM Score
| s_id | c_id | s_score | current_sum | current_avg | count_ | max_score | min_score |
|---|---|---|---|---|---|---|---|
| 01 | 03 | 99 | 99 | 99.0000 | 1 | 99 | 99 |
| 07 | 03 | 98 | 197 | 98.5000 | 2 | 99 | 98 |
| 01 | 02 | 90 | 287 | 95.6667 | 3 | 99 | 90 |
| 01 | 01 | 80 | 527 | 87.8333 | 6 | 99 | 80 |
| 02 | 03 | 80 | 527 | 87.8333 | 6 | 99 | 80 |
| 03 | 01 | 80 | 527 | 87.8333 | 6 | 99 | 80 |
| 05 | 01 | 76 | 603 | 86.1429 | 7 | 99 | 76 |
| 02 | 01 | 70 | 673 | 84.1250 | 8 | 99 | 70 |
| 02 | 02 | 60 | 733 | 81.4444 | 9 | 99 | 60 |
| 04 | 01 | 50 | 783 | 78.3000 | 10 | 99 | 50 |
| 06 | 03 | 34 | 817 | 74.2727 | 11 | 99 | 34 |
| 06 | 01 | 31 | 848 | 70.6667 | 12 | 99 | 31 |
| 04 | 02 | 30 | 878 | 67.5385 | 13 | 99 | 30 |
| 04 | 03 | 20 | 898 | 64.1429 | 14 | 99 | 20 |
- 先按照c_id字段分组,分组之后按照s_score升序排列。注意所有的聚合操作都是在分组内进行,组与组之间没有联系。
#既有order by,又有partition的查询
SELECT s_id, c_id, s_score,
SUM(s_score) OVER (PARTITION BY c_id ORDER BY s_score) AS current_sum,
AVG(s_score) OVER (PARTITION BY c_id ORDER BY s_score) AS current_avg,
COUNT(s_score) OVER (PARTITION BY c_id ORDER BY s_score) AS count_,
MAX(s_score) OVER (PARTITION BY c_id ORDER BY s_score) AS max_score,
MIN(s_score) OVER (PARTITION BY c_id ORDER BY s_score) AS min_score
FROM Score
| s_id | c_id | s_score | current_sum | current_avg | count_ | max_score | min_score |
|---|---|---|---|---|---|---|---|
| 04 | 01 | 50 | 81 | 40.5000 | 2 | 50 | 31 |
| 06 | 01 | 31 | 31 | 31.0000 | 1 | 31 | 31 |
| 02 | 01 | 70 | 151 | 50.3333 | 3 | 70 | 31 |
| 05 | 01 | 76 | 227 | 56.7500 | 4 | 76 | 31 |
| 01 | 01 | 80 | 387 | 64.5000 | 6 | 80 | 31 |
| 03 | 01 | 80 | 387 | 64.5000 | 6 | 80 | 31 |
| 04 | 02 | 30 | 30 | 30.0000 | 1 | 30 | 30 |
| 02 | 02 | 60 | 90 | 45.0000 | 2 | 60 | 30 |
| 01 | 02 | 90 | 180 | 60.0000 | 3 | 90 | 30 |
| 04 | 03 | 20 | 20 | 20.0000 | 1 | 20 | 20 |
| 06 | 03 | 34 | 54 | 27.0000 | 2 | 34 | 20 |
| 02 | 03 | 80 | 134 | 44.6667 | 3 | 80 | 20 |
| 07 | 03 | 98 | 232 | 58.0000 | 4 | 98 | 20 |
| 01 | 03 | 99 | 331 | 66.2000 | 5 | 99 | 20 |
滑动窗口
# 对前n行(包括当前行),求<窗口函数>的值
<窗口函数> OVER (ORDER BY <排序列名> ROWS n PRECEDING)
# 对前n行到后n行,求<窗口函数>的值
<窗口函数> OVER (ORDER BY <排序列名> ROWS BETWEEN n PRECEDING AND n FOLLOWING)
# UNBOUNDED PRECEDING表示分组内的第一行,UNBOUNDED FOLLOWING表示分组内的最后一行
<窗口函数> OVER (PARTITIOIN BY <分组列名> ORDER BY <排序列名> ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
SELECT s_id, c_id, s_score,
SUM(s_score) OVER (PARTITION BY c_id ORDER BY s_score ROWS 2 PRECEDING) AS current_sum,
AVG(s_score) OVER (PARTITION BY c_id ORDER BY s_score ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS current_avg,
MAX(s_score) OVER (PARTITION BY c_id ORDER BY s_score ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS max_score
FROM Score
| s_id | c_id | s_score | current_sum | current_avg | max_score |
|---|---|---|---|---|---|
| 06 | 01 | 31 | 31 | 40.5000 | 80 |
| 04 | 01 | 50 | 81 | 50.3333 | 80 |
| 02 | 01 | 70 | 151 | 65.3333 | 80 |
| 05 | 01 | 76 | 196 | 75.3333 | 80 |
| 01 | 01 | 80 | 226 | 78.6667 | 80 |
| 03 | 01 | 80 | 236 | 80.0000 | 80 |
| 04 | 02 | 30 | 30 | 45.0000 | 90 |
| 02 | 02 | 60 | 90 | 56.6667 | 90 |
| 03 | 02 | 80 | 170 | 75.6667 | 90 |
| 05 | 02 | 87 | 227 | 85.3333 | 90 |
| 07 | 02 | 89 | 256 | 88.6667 | 90 |
| 01 | 02 | 90 | 266 | 89.5000 | 90 |
| 04 | 03 | 20 | 20 | 27.0000 | 99 |
| 06 | 03 | 34 | 54 | 44.6667 | 99 |
| 03 | 03 | 80 | 134 | 64.6667 | 99 |
| 02 | 03 | 80 | 194 | 86.0000 | 99 |
| 07 | 03 | 98 | 258 | 92.3333 | 99 |
| 01 | 03 | 99 | 277 | 98.5000 | 99 |